Created by Kristoffer Magnusson
Type I and Type II errors, β, α, p-values, power and effect sizes – the ritual of null hypothesis significance testing contains many strange concepts.
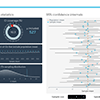
Much has been said about significance testing – most of it negative. Methodologists constantly point out that researchers misinterpret p-values. Some say that it is at best a meaningless exercise and at worst an impediment to scientific discoveries. Consequently, I believe it is extremely important that students and researchers correctly interpret statistical tests. This visualization is meant as an aid for students when they are learning about statistical hypothesis testing. The visualization is based on a one-sample Z-test. You can vary the sample size, power, significance level and the effect size using the sliders to see how the sampling distributions change.
The visualization will show that "power" and "Type II error" is "-" when d is set to zero. However, the Type I error rate implies that a certain amount of tests will reject H0. It is tempting to also say that this ratio is the test's "power", and frequently textbooks and software do just that. Some sources also say that power is zero when H0 is equal to Ha. My view is that power is not defined when the assumed effect is an element of H0's parameter space. When this is the case, the power function returns α, and therefore "power" is undefined. So even though the power function says 5 % of the tests will reject the null, it does not make sense to talk about "power" here. This also implies that as Ha approaches H0 power will approach α for small values of d. As a result the slider for "power" isn't allowed to be equal to or less than α.
The content on this blog is shared for free under a CC-BY license. If you like my work and want to support it you can:
![]() Buy me a coffee (or use PayPal)
Buy me a coffee (or use PayPal)
You can also sponsor my open source work using GitHub Sponsors
The following quotes might spark your interest in the controversies surrounding NHST.
"What's wrong with [null hypothesis significance testing]? Well, among many other things, it does not tell us what we want to know, and we so much want to know what we want to know that, out of desperation, we nevertheless believe that it does!"
“… surely the most bone-headedly misguided procedure ever institutionalized in the rote training of science students"
“… despite the awesome pre-eminence this method has attained in our journals and textbooks of applied statistics, it is based upon a fundamental misunderstanding of the nature of rational inference, and is seldom if ever appropriate to the aims of scientific research”
“… an instance of a kind of essential mindlessness in the conduct of research" – Bakan (1966)
“Statistical significance testing retards the growth of scientific knowledge; it never makes a positive contribution”
“The textbooks are wrong. The teaching is wrong. The seminar you just attended is wrong. The most prestigious journal in your scientific field is wrong."